脚本如下,逻辑是读取根目录下的所有文件,以UTF-8 with BOM的编码格式打开,然后以UTF-8 without BOM的编码格式保存。如果文件本身是UTF-8 with BOM的编码格式,被处理后会将前面3个字节去掉。如果文件本身是UTF-8 without BOM的编码格式,那么会先以UTF-8 with BOM的编码格式打开(会在前面新增3个字节),然后再以UTF-8 without BOM的编码格式保存(去掉前面新增的3个字节),所以最终的结果是所有文件都被修改为UTF-8 without BOM的编码格式了。
1
2
3
4
5
6
7
8
9
10
11
12
import os
root_path = r"E:\haha"
count = 0
for path, subdirs, files in os.walk(root_path):
for name in files:
file = os.path.join(path, name)
print(file)
s = open(file, mode='r', encoding='utf-8-sig').read() # UTF-8 with BOM
open(file, mode='w', encoding='utf-8').write(s) # UTF-8 without BOM
count +=1
print("共",count,"个文件,转换完毕")
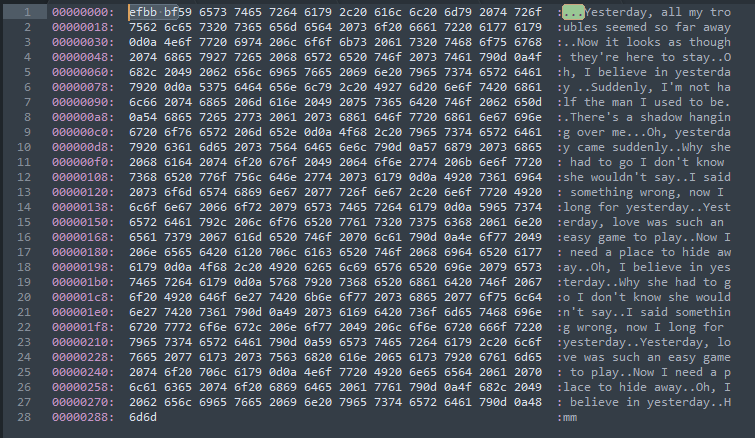
UTF-8 without BOM的文件示例(以16进制打开)
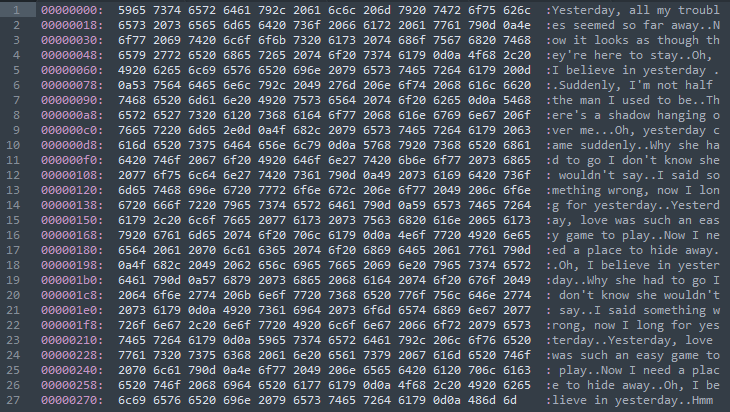 UTF-8 with BOM的文件示例(以16进制打开),可以看到前面多了3个字节,后面的内容和上面一样
UTF-8 with BOM的文件示例(以16进制打开),可以看到前面多了3个字节,后面的内容和上面一样