最近的测试工作中有涉及到埋数。在金融行业的风控体系测试中,我们需要调用各种第三方接口,比如人行征信,算话,汇法,芝麻分等等。在测试过程中,我们是无法调用实时接口去查询真实数据的。一来这些接口的调用查询需要花钱,二来我们无法预先知道我们查询出的结果是什么样的。在测试中,我们需要知道我们的期望结果。正因为这样,我们需要在测试数据库中预埋数据,测试时通过接口查询本地数据即可。
在设计完测试场景后,我们就一个场景一个场景的准备数据。这些数据涉及到了很多张数据表,在人工准备数据的时候,我们是按照场景准备的数据,但只要是人操作的东西,就有可能会出错。为了达到我们准备的数据有正确的期望结果,我们需要对这些数据进行提取验证。
准备的数据通常是放在Excel中的,虽然在Excel中也可以写VBA一类的脚本来提取数据,但是本人用VBA写过一次Excel的数据操作,但不是非常熟练。所以转向到了通过python来实现。通过一番Google,发现通过pandas和pandasql这2个模块就可以完成任务了。
pandas用来读取Excel中的数据到DataFrame对象中,每一个DataFrame对象可以看做一张数据库中的数据表。pandasql可以对DataFrame对象执行sql操作,包括多表组合查询等等。最终再使用pandas将查询出来的结果(也是DataFrame对象)写入Excel。
示例脚本如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import pandas as pd
from pandasql import *
pysqldf = lambda q: sqldf(q, globals())
RESULT_INFO = pd.read_excel("sample.xlsx", sheet_name = "RESULT_INFO")
NUMREADER_INFO = pd.read_excel("sample.xlsx", sheet_name = "NUMREADER_INFO")
a = """
select r.NAME, n.NUM_READER, r.REPORT_CREATE_TIME from RESULT_INFO r Left Join NUMREADER_INFO n
where r.REPORT_SN = n.REPORT_ID;
"""
result = pysqldf(a)
print(result)
print(type(result))
result.to_excel("result.xlsx")
命令行输出结果示例:
1
2
3
4
5
6
7
8
PS D:\Tesla\Pandas> python .\mytest.py
NAME NUM_READER REPORT_CREATE_TIME
0 杨磊 922.0 2016.12.15 21:48:20
1 莫林霖 819.0 2017.01.12 22:33:33
2 陈大成 950.0 2017.01.12 20:17:04
3 吴婷婷 500.0 2017.01.13 09:23:46
4 侯国平 719.0 2017.02.23 13:44:42
5 王丽丽 760.0 2017.02.23 13:44:54
Excel输出结果示例:
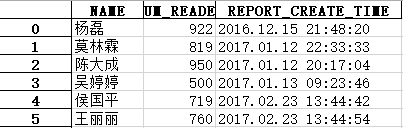
决策模拟脚本示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import pandas as pd
from pandasql import *
pysqldf = lambda q: sqldf(q, globals())
user = pd.read_excel("input.xlsx")
decision_result = []
for index, row in user.iterrows():
# 事件一决策
if row['AGE'] < 20 or row['AGE'] > 50:
event_one = 'N'
event_one_des = '客户年龄小于20或者大于50,被拒;'
else:
event_one = 'Y'
event_one_des = '事件一通过'
# 事件二决策
if event_one == 'Y':
if row['LIMIT'] < 1000 or row['LIMIT'] > 50000:
event_two = 'N'
event_two_des = '额度在1000-50000之外,被拒;'
else:
event_two = 'Y'
event_two_des = '事件二通过'
else:
event_two = '未进入事件二'
event_two_des = '未进入事件二'
print(event_one,event_one_des,event_two,event_two_des)
decision_result.append([event_one,event_one_des,event_two,event_two_des])
df=pd.DataFrame(decision_result,columns=['event_one','event_one_des','event_two','event_two_des'])
print('--------------------------')
print(df)
决策脚本命令行输出示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
PS D:\Tesla\Pandas> python .\decision.py
Y 事件一通过 Y 事件二通过
N 客户年龄小于20或者大于50,被拒; 未进入事件二 未进入事件二
Y 事件一通过 Y 事件二通过
Y 事件一通过 Y 事件二通过
Y 事件一通过 Y 事件二通过
Y 事件一通过 Y 事件二通过
--------------------------
event_one event_one_des event_two event_two_des
0 Y 事件一通过 Y 事件二通过
1 N 客户年龄小于20或者大于50,被拒; 未进入事件二 未进入事件二
2 Y 事件一通过 Y 事件二通过
3 Y 事件一通过 Y 事件二通过
4 Y 事件一通过 Y 事件二通过
5 Y 事件一通过 Y 事件二通过