目的
之前使用过C#,Java做过自动化测试,由于在测试技术领域,python几乎可以通吃,所以想把测试技术栈都移到python。在看过不少资料后,决定自己把框架重新搭建一下,期望达到换一个项目也能直接使用,只需要针对不同的测试页面写测试脚本即可的目的。
选择pytest的原因,是因为pytest是一个非常不错的测试框架,而且在接口测试,单元测试等中也可以使用,而且能很好地和allure报告结合。allure报告是一个非常漂亮高大上的报告,能很方便地和CI集成,整个测试执行完毕后,测试报告结果是可以指定在测试代码目录外的其他目录的,所以看上去很整洁干净。
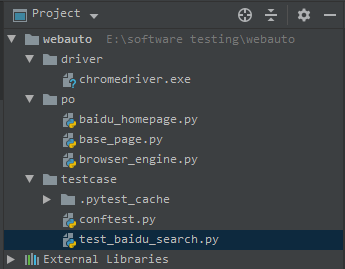
框架的目录结构
browser_engine.py
用来实现一个webdirver的单例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from selenium import webdriver
class BrowserEngine(object):
chrome_driver_path = '../driver/chromedriver.exe'
def __init__(self, selenium_driver):
self.driver = selenium_driver
def get_driver(self):
selenium_driver = webdriver.Chrome(self.chrome_driver_path)
selenium_driver.maximize_window()
selenium_driver.implicitly_wait(10)
return selenium_driver
base_page.py
用来封装webdriver的方法,目前只把查找元素和隐式等待进行封装,其他的根据需要再添加即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class BasePage:
def __init__(self, selenium_driver):
self.driver = selenium_driver
def find_element(self, *loc):
try:
WebDriverWait(self.driver, 10).until(EC.visibility_of_element_located(loc))
return self.driver.find_element(*loc)
except:
print("%s 页面未能找到 %s 元素" % (self, loc))
baidu_homepage.py
这是百度搜索页面的元素定位和操作。虽然测试内容简单,但是思想都在里面了。其他的无非就是不同的页面,不同的元素定位和操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import time
from po.base_page import BasePage
from selenium.webdriver.common.by import By
import allure
class BaiduHomePage(BasePage):
search_box_loc = (By.ID, "kw")
search_button_loc = (By.ID, "su")
@allure.step('打开百度首页')
def open_homepage(self):
self.driver.get('https://www.baidu.com/')
@allure.step('输入内容进行搜索')
def search(self, search_char):
search_box = self.find_element(*self.search_box_loc)
search_box.send_keys(search_char)
search_button = self.find_element(*self.search_button_loc)
search_button.click()
time.sleep(3)
@allure.step('验证标题是否正确')
def verify(self, verify_char):
title = self.driver.title
print(title)
assert verify_char == title
test_baidu_search.py
拼接起来的百度搜索页面测试用例,其中用到了pytest的parametrize来实现参数化。若有其他的需求,比如数据驱动,可以根据需求选择用excel或yaml或python字典等来存放测试数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import sys
sys.path.append("..")
from po.browser_engine import BrowserEngine
from po.baidu_homepage import BaiduHomePage
import pytest
import allure
@allure.feature("百度搜索")
class TestBaiduSearch:
@classmethod
def setup_class(cls):
browse = BrowserEngine(cls)
cls.driver = browse.get_driver()
@classmethod
def teardown_class(cls):
cls.driver.quit()
@allure.story("测试百度搜索,验证标题是否正确")
@pytest.mark.parametrize("search_char, verify_char", [('龙珠', '龙珠_百度搜索'), ('火影忍者', '火影_百度搜索')])
def test_baidu_search(self, search_char, verify_char):
baidu_homepage = BaiduHomePage(self.driver)
baidu_homepage.open_homepage()
baidu_homepage.search(search_char)
baidu_homepage.verify(verify_char)
if __name__ == '__main__':
pytest.main()
conftest.py
这个pytest框架中的特定文件,必须写成conftest.py,我在这里主要写了1个钩子函数,用来监听测试用例的执行情况,若发现失败,会自动将失败当时的页面进行截图,并保存到allure报告中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import pytest
import allure
from allure_commons.types import AttachmentType
from PIL import ImageGrab
from io import BytesIO
@pytest.hookimpl(tryfirst=True, hookwrapper=True)
def pytest_runtest_makereport():
outcome = yield
rep = outcome.get_result()
if rep.when == "call" and rep.failed:
with BytesIO() as output:
img = ImageGrab.grab()
img.save(output, 'PNG')
data = output.getvalue()
allure.attach(data, name="异常截图", attachment_type=AttachmentType.PNG)
脚本的执行方法
- 先新建2个目录,用来存放allure结果和html报告。比如说allure结果E:\my_allure_results,html报告E:\my_allure_html
- 在命令行中切换到testcase目录,执行pytest –alluredir=E:\my_allure_results
- 查看报告,执行allure serve E:\my_allure_results
- 生成html报告,执行allure generate E:\my_allure_results -o E:\my_allure_html
allure模块的安装
1
pip install allure-pytest
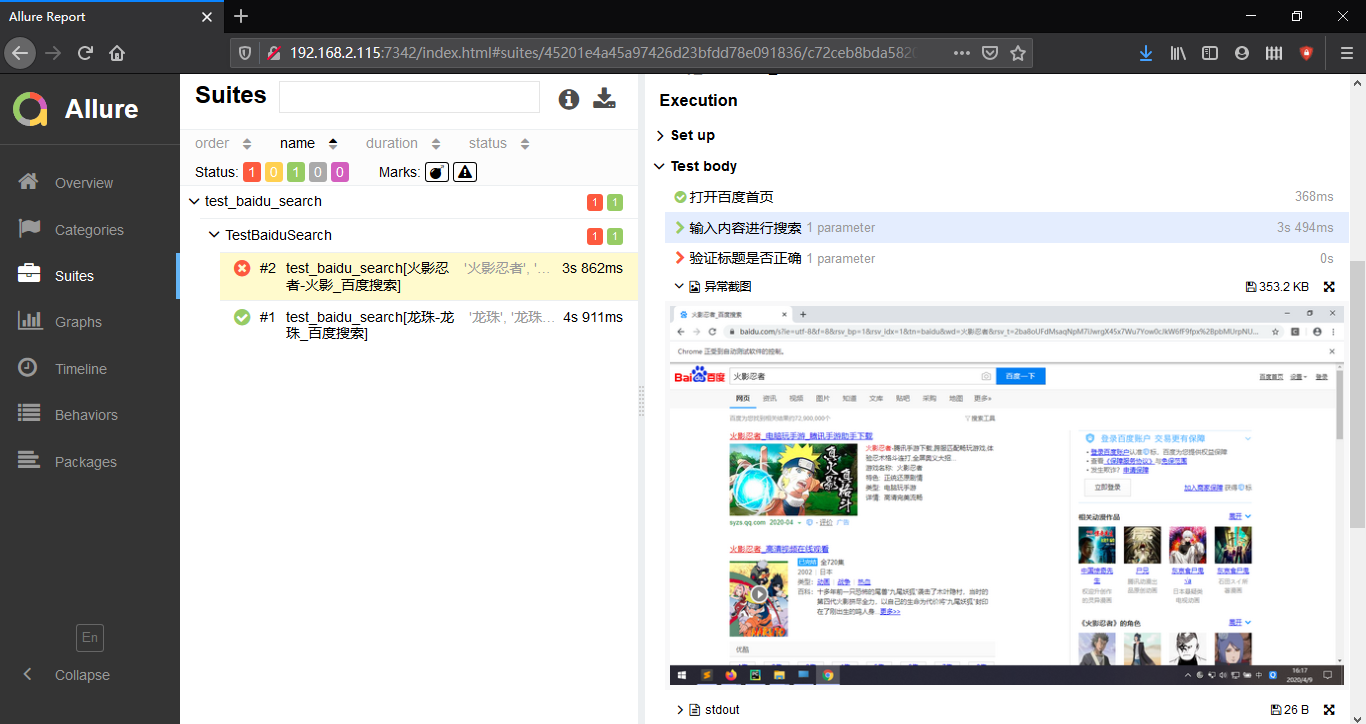
测试报告样例展示